
Attention is all you need (in the brain): semantic contextualization in human hippocampus
How the brain uses the same transformer architecture that makes LLMs work

Kalman A. Katlowitz, James L. Belanger*, Taha Ismail*, Ana G. Chavez, Assia Chericoni, Melissa Franch, Elizabeth A. Mickiewicz, Raissa K. Mathura, Danika L. Paulo, EleonoraBartoli, Steven T. Piantadosi, Nicole R. Provenza, Andrew J. Watrous, Sameer A. Sheth**,and Benjamin Y. Hayden**
*/** denotes co-equal authorship
All authors (except STP): Neurosurgery, Baylor College of Medicine, and Neuroengineering, Rice University
STP: Psychology, UC Berkeley
Published in Nature Human Behavior, July 1, 2026. Download the PDF here. Access the webpage here.
See the github for data and code here.
One of the key insights that allowed for the development of large language models is the transformer architecture (Vaswani et al., 2017). Rather than compute semantic embeddings for each word alone, words affect the semantic embeddings for other words. So, for example, the word ball might refer to any of a large number of types of balls, or even a formal dance. But a tennis ball is a particular kind of ball. The word tennis modifies ball. It imbues it with the associations of tennis (like a tennis court, a tennis racket, famous tennis players, etc). And it does this by rotating the "ball' vector towards the vector for "tennis". The amount of rotation can vary on a word by word basis.

We wanted to know whether the human brain uses the same principles. (Spoiler: it does).
To test this idea, we need responses of single neurons in the brain during speech listening. We collected data from ten patients undergoing monitoring for epilepsy at Baylor/St. Luke's Hospital in Houston, Texas. All patients had electrodes in the hippocampus, a region that is critical for semantic representations (Franch et al., 2026; Katlowitz et al., 2026; Yan et al., 2026).

Picture of the human brain showing the location of the hippocampus, a region that plays a key role in representing word meanings (in yellow).
We recorded data from electrodes at the points indicated by the dots.
The first thing any transformer architecture needs is some way to map the space of words. That is, the brain needs to keep track of where in a clause a given word is, so that it can perform the appropriate weightings. We find that hippocampal neurons use three separate principles to map word position:
-
There is a gradual increase in firing with word number in clause. This resembles an effect previously observed in LFP (Nelson et al., 2017). In that study it was attributed to memory load; we tried to test that idea by controlling for opening/closing node number, but didn't see any changes - suggesting it might not only be memory.
-
Neurons fire most strongly for a particular word (e.g., the fourth word in a clause). This is reminiscent of positional encoding (Vaswani et al., 2017). Interestingly, individual neurons often coded for multiple positions, reminiscent of a multi-peaked code.
-
Neurons have a periodic code (e.g., third word, sixth word, ninth word, etc). Across the population, peak frequencies approximately tiled the frequency space, as would be predicted by an efficient code. This periodic code is reminiscent of rotary position encoding (Su et al., 2021), and it's powerful because it allows scaling for arbitrarily long clauses.
Why the brain has these seemingly redundant principles, we don't know. It could be that each of them has benefit in some way.
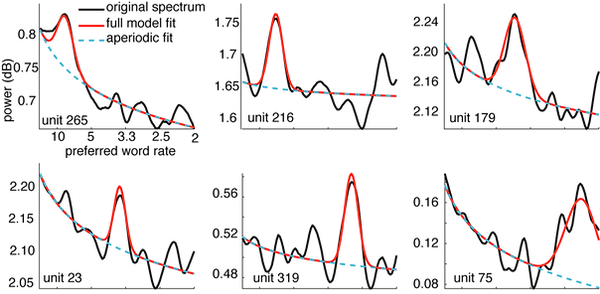
Examples of single neurons with periodic codes. Plots of the power spectra of six neurons with the aperiodic fit overlaid. Significant deviations shown in red.
For example, unit 178 (upper right panel) has an enhanced response to every fifth word, while unit 23 (lower left panel) has an enhanced response to every fourth word.
Now we will look at contextualization directly. The word "bat" can have different meanings determined by context. If it's used in the context of flying or vampire we might think of the mammal; if it's used in the context of swing or umpire, we might think of a baseball bat. These words exert their influence by rotating the embedding vector for bat towards them.

How attention works:
Contextualizing words influence the words they contextualize by rotating their embedding vectors towards them.
(There's other stuff too, but this is one way).
We looked at some well-known contextualizations in English. Probably the most famous one is adjective-noun pairings (Pylkkänen, 2019). The word "sunny" can modify "day" by shifting its meaning in the phrase "sunny day". Grammatically, this is expressed in the noun phrase construction process. Notably, this does not require adjacency - we could say, for example, "it was a sunny, but not particularly warm, day" and the word "sunny" would still modify "day" in (approximately) the same way.
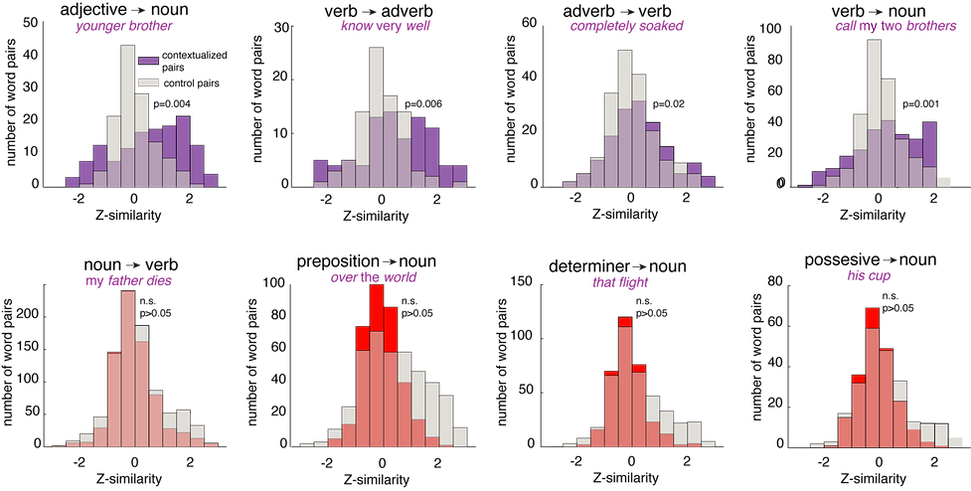
We find, looking at our neural data, that neural population responses to each words are rotated towards the neural population responses of the contextualizing word, at least for four categories of relationships. This includes adjective→noun, verb→adverb, adverb→verb, and verb→noun (generally nominal objects). Other ones, we did not see any significant effect. Of course, we cannot conclude there is no effect there. And some of these, such as determiner→noun may by explained by the fact that determiners are very semantically bleached, and dont have strong embeddings.
In other words, in the population neural response to any given word, we can see traces of the words that contextualize it. The response to "ball" in the phrase "tennis ball" carries factors associated with "tennis". So the brain does not simply represent the meanings of words the way a dictionary does - it represents words in a contextualized manner.
Next we asked whether the amount of neural contextualization matches, quantitatively, the amount of attention for each word in GPT2. (Yes, it does).

Quantitative match between neural attention and LLM attention.
In one example sentence, we show the weightings for each word on the final word ("team"). Unrelated words ("probably", "he's") have low weightings, while related words ("people", "football") have high weightings.
These LLM-derived weightings (red bars) have a quantitative match with the neural-derived weights (blue bars). The neural-derived weights are calculated without using the LLM.
We can feed our entire podcast into GPT2 and calculate the embeddings for each word. There are multiple attention heads linking each word to each other word, but, for this study, we can just look at the average of all of the contextualizing words. (For a really cool study disentangling the attention heads, check out Kumar et al., 2024).
This is called the attention pattern grid (APG, Vig, 2019). Basically, we wanted to reconstruct the APG using neural data. We will do this for each layer of GPT2 (there are 36 layers).

Degree of match between LLM-derived APG and the "neural APG" for each window size and GPT layer. The neural APG is a concept we introduce here, where we use neural responses to infer the shape of the presumed APG (that is how much semantic influence each word has on each other word). We then compare this to the corpus-derived APG (from GPT2, but it also works with LLAMA). While we see a match for all combinations, the strongest match occurs in mid-to-high layers, consistent with the idea that these include more contextualization than lower layers.
These effects are not only due to adjacency. There's a clear correspondence on a word-by-word level.

DISCUSSION
Word we hear are represented in the brain in the form of patterns in populations of neurons. The is population response allows you to do lots of powerful things you can't do with single neurons (Ebitz and Hayden, 2021). One of these is contextualization by vector rotation. That's how it works in LLMs; our data suggest the brain may use a similar principle.
The fact that we see explicit neural codes for location within a clause tells is that the hippocampus maps word position just like it does space, time, reward, and concepts. What's really cool is the periodic coding, which allows for scaling.
One of the core features of grammar is the binding of elements to create newer elements ("merge", Hauser et al., 2022). Merge remains controversial (Everett, 2005; Jackendoff and Pinker, 2005). Attention architecture offers an alternative pathway, one with a very different flavor than Chomskian approaches, but with the potential to implement core grammatical functions. And unlike Chomskian approaches, they are congenial with, rather than inimical to, neuroscience.
Further reading: